Re-Resolve the Depth!
Back again..With all that crazy stuff going around, i had some time to work on Mirage, while there are things being added, and Mirage look qutie different now, but the one i wanna spotlight in that post is a modification of an existing thing. This been in writing for quite sometime (several months), as i do like to wrap every weekend’s updates (which is not much) in an on going draft post to share later when done.
Remember the previous time when talked about the MSAA depth, the methods that can be used and what i done to achieve that..I needed to re-wrok that part again, and change all that…
But Why?
When a new Vk SDK is out, I don’t usually get it into Mirage, i do only download and install it, but not use it in Mirage. I could possibly skip every couple SDK updates to be the one used in the engine and then get the third release may be. There is no fancy deep reason behind that, except that me wants to avoid any possible issues, as long as there is an on going feature being worked. As getting a new SDK while in the middle of working on a new feature, if started to get errors, i might get lost for a while in the confusion if that issue is caused by my in progress work, or caused by the new SDK or even by a new driver update.
Anyways, since I updated Mirage’s dependencies to one of the latest 1.2 versions (I assume 1.2.135.0 or 1.2.141.0), i started to get validation errors from the validation layers, and this is expected due to the fact of the on going perfection of the API, as well as the on going restrictions or rules been added in every new release.
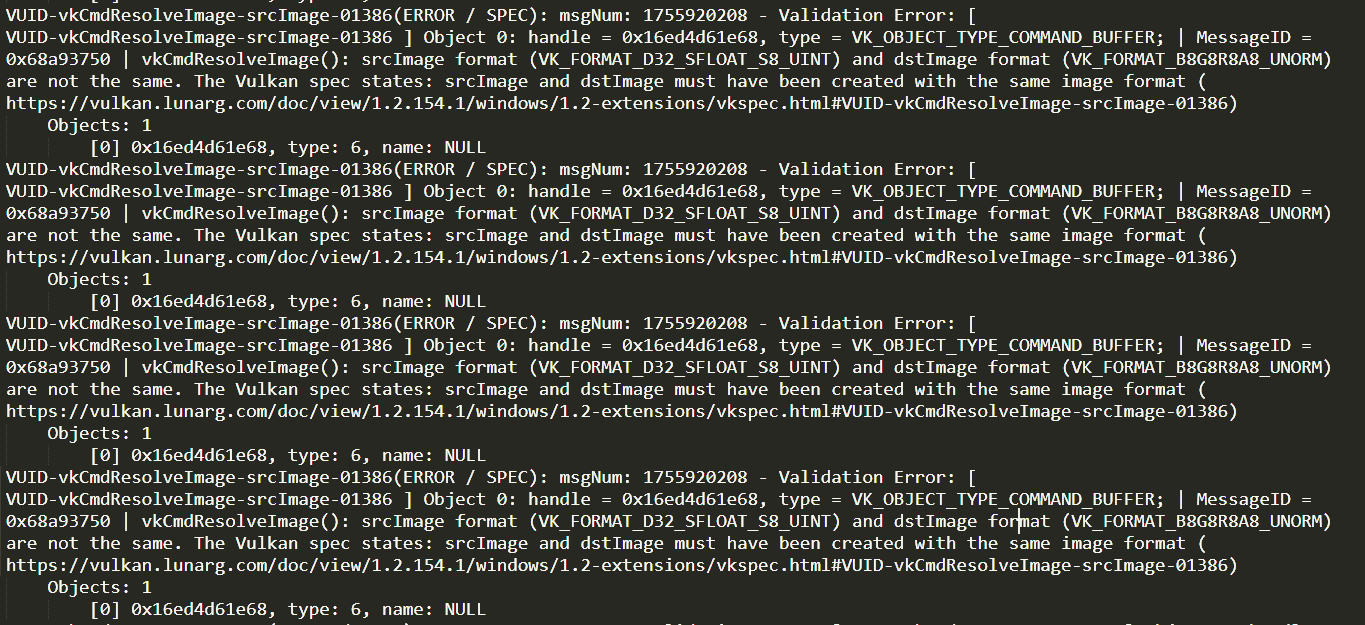
While it was working previously, just before i change the project settings and the shader compiler to the new SDK version, it was never considered illegal by the the validation layer at all!! Of course it is still working, and the result still present at runtime, and even better it runs totally fine at Release build of Mirage (no validation layers). But the only issue is seeing those errors while running a debug version of Mirage (continues endless errors). My rule of thumb with vulkan so far is to enable all the validation layers, and to always make sure the console of a debug version is always errors free. So i wanted to solve this one, without any work arounds, and solved it once and for all..
What is the Change?
I decided to go back again to the initial plan…using the API’s VkSubpassDescriptionDepthStencilResolve that is introduced in 1.2.x. After all i won’t be supporting 1.0 forever, specially while there is no plans so far to run this engine outside my PC!
And in order to do that transition and to successfully use the built-in subpass depth stencil resolve, there are quite a handful amount of thing need to be changed.
First, need to make sure the VkApplicationInfo is targeting the 1.2 version. Guess what, I did work on the feature, and i see no result, but at the same time, i see neither compile errors nor runtime validation layer errors. And the reason was only to change 1.0 to 1.2 of the apiVersion member of the VkApplicationInfo.
Second, as the API sepcs mention:

This meant the Subpass description now need to be VkSubpassDescription2 instead of VkSubpassDescription. And hence, things such as VkAttachmentDescription would be VkAttachmentDescription2, and VkAttachmentReference would be VkAttachmentReference2, and of course VkSubpassDependency2 instead of VkSubpassDependency, and VkRenderPassCreateInfo2 instead of VkRenderPassCreateInfo, and even creating the renderpass via vkCreateRenderPass2() not vkCreateRenderPass(). And again, as mentioned before, this is not only a matter of renaming the struct types i use, but also introducing new structs to be used for some members that were not used in the default API, or new members that was not exist at all at the default API. Some aspect masks would be changed (or even set while it was never required before), some image layouts would be changed, fixes here and changes there in order to change the purpose and use of the resolved depth attachment image to fit the new resolve and present method.
But even with that..Nothing would work!
While doing some research, i did found a useful talk from GDC19 during the Khronos Dev Day, so i would like to leave it here for reference. In that talk, Lewis Gordon of Samsung, mentions not only the history behind that depth resolve feature of 1.2, but also the requirements, the performance, as well as the exact extensions that i need to enable, in order to let the feature work properly. Yet, before that video, i was only enabling the VK_KHR_DEPTH_STENCIL_RESOLVE_EXTENSION_NAME device extension as mentioned here. But seemed from the GDC talk below that this in not enough in order to make the thing work. But thankfully after enabling those other “dependencies” extensions, all worked like charm!
The Result..
Results are fascinating! Check below.

open in new tab to see in full detail
– First row, is MSAA disabled, where the second row is MSAA enabled.
– Left to right, Color attachment, Depth attachment, Split visualization view.
– Open the image in a new tab, to see it full screen, so you could be able to see the difference (if not visible in here).
One last thing, while there are penalty of VkResolveModeFlagBits that can be used for either the depth or the stencil as seen in the official page or the image below. But for depth, it never showed nice results until the VK_RESOLVE_MODE_AVERAGE_BIT is the one set as the depthResolveMode of the VkSubpassDescriptionDepthStencilResolve.

How much would you pay $$$?
And at both cases we can of course check the cost, if not, what’s the point!
For the first glance it seem it costed almost nothing when i was using the manual resolve for the images via the vkCmdResolveImage() as you can see the time spent is “-“ CPU/GPU in the image below for each resolve cmd call. But this is not true. The trick is, the CPU is idle already for 3.31ms after the command buffer is ended (the command buffer made for the resolve commands) and before that cmd buffer is totally free. This is due to the resolve image resources. So yes, while the CPU/GPU time for the actual call itself is showing no time spent, but actually the resolve is kinda time consuming in this method.
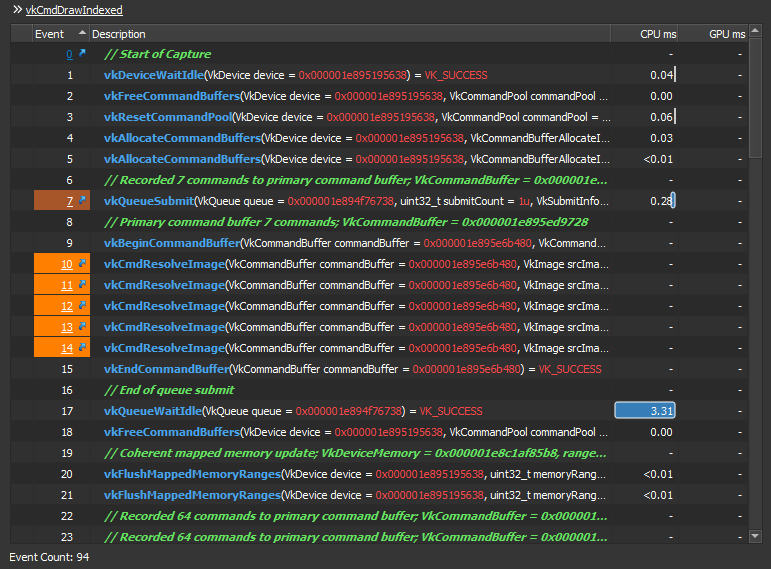
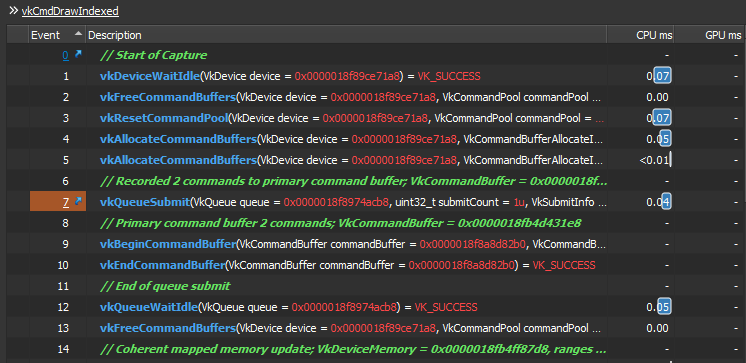
In order to prove it further, here is another capture with the entire resolve calls vkCmdResolveImage() are all skipped. We only vkBeginCommandBuffer() for the resolve, but no actual resolve commands, we right away end that command buffer vkEndCommandBuffer(). You can notice that the queue idle now is reduced from 3.31ms to 0.05ms. Voila!
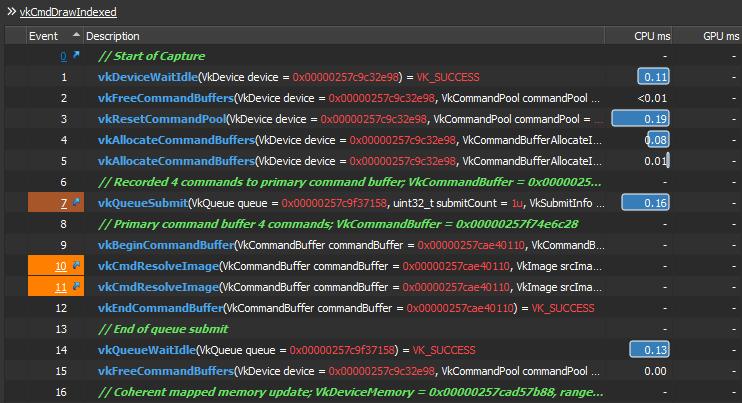
And to prove this point more, and to have a very clear confirmation on the cost of that command and better digestion on how it impacts the renderer. I did increase the number of the vkCmdResolveImage() calls again within the resolve cmd buffer, from 0 to 2. I do have multiple ones for multiple reasons/usages. But i did only two resolve commands this time (to compare with the first/origianl capture), and the Idle went high again, but not as Hight as the first time, only 0.13ms this time. Which means we have roughly 0.066ms idle per single vkCmdResolveImage() call this time!! So the idle time per single call would be increased with the number of the calls. Where here we have 0.066ms idle per single call when called resolve cmd twice, previously we had 0.66ms idle per single call when we called five resolve cmds..This is 10 times the cost. Which is INSANELY unnecessary idle time that we need to avoid!!
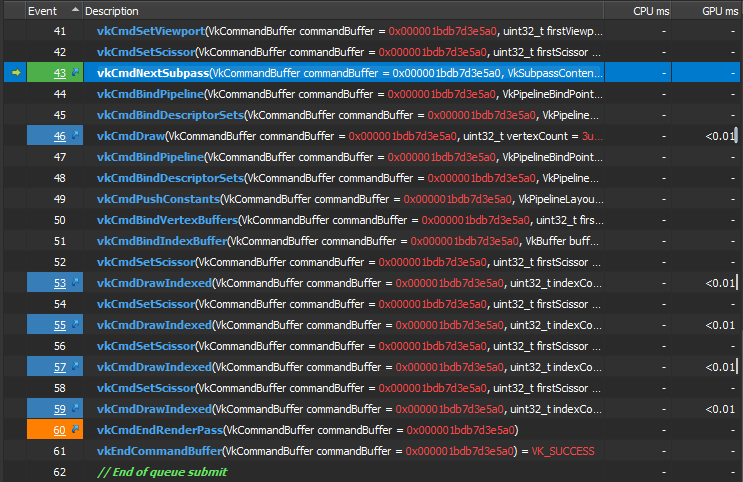
At the other hand, it defiantly remains zero cost with the VkSubpassDescriptionDepthStencilResolve method. Despite the fact this resolve is not traced as a function call (command to be more accurate) by the GPU frame profiler, but as I know it happens during the 1st subpass and before/while going to the 2nd subpass, then it’s enough to look around the vkCmdNextSubpass() to measure the cost roughly. Which is already nothing until the next draw command!
I guess that’s all folks for now!
And yeah, I’ve to work more in my naming skills, branches names are getting out of control recently…

-m







