Arabic Decoding for Games & Game Engines – Part 5: Diacritics
Parts of the Series
This series consist of 6 parts:
- Arabic Decoding for Games & Game Engines – Part 1: Challenges
- Arabic Decoding for Games & Game Engines – Part 2: Decoding
- Arabic Decoding for Games & Game Engines – Part 3: Formations
- Arabic Decoding for Games & Game Engines – Part 4: Lam-Aleph
- Arabic Decoding for Games & Game Engines – Part 5: Diacritics
- Arabic Decoding for Games & Game Engines – Part 6: Multi-Language
After celebrating the victory of correctly rendered Arabic from Right to Left, we hit a solid ground with a fully broken Arabic again with the addition of text that has diacritics!

Specially that if we wrote the exact same text, but without diacritics, it will render just fine with the current state of our system.

But why?
The Problem
To understand it well, we need to simplify the issue. I’ll be setting the text to a single word, that is الشكر and see what glyphs we’re pushing to the atlas while validating the word (very early before we do quads or draw).

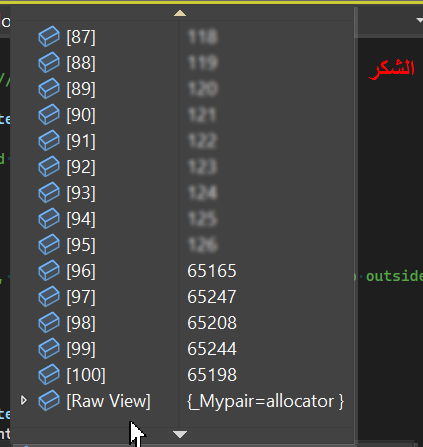
You would notice that the one at the left (the one with diacritics) have generated few more codepoints, that are 1617, 1615 and 1618. And by checking this in the codepoints search, we can see that these 3 are belonging to the diacritic moves that decorating the Arabic characters of this test word.


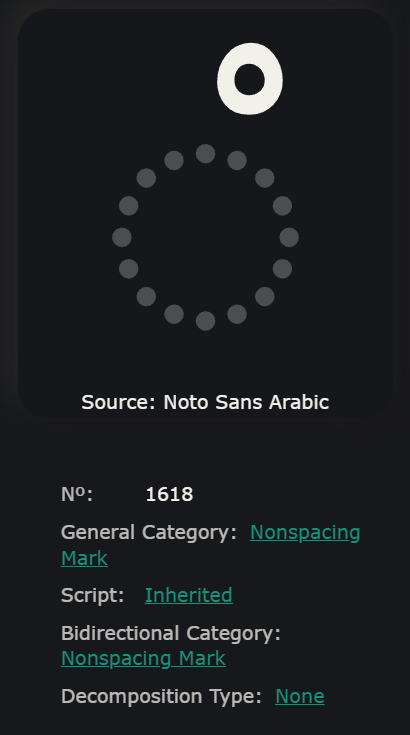
So this means that diacritics are held in their own codepoints, and they’re not part of the characters they are decorating! Let’s say not like the Latin alphabet (English, French,..etc.), where a diacritic or marking for the character is part of the character itself & the entire codepoint is holding the glyph of the character + the diacritic shape.

And this mean the current UI system will consider the Arabic diacritics as an “individual” characters (this is bad), and hence, will consider them as a Previous and a Next to the actual characters near to them in the codepoints cache list when generating forms (this is wrong), not only that, but also will advance the rendering/drawing cursor forward after drawing each of diacritics (this is bad), which will mess up the offset of everything, as now we will be drawing quad for a character, then advance forward, then draw a quad for a diacritic, then advance forward, and then draw whatever next,…etc. which is wrong, because diacritics should not advance the cursor after being rendered to screen! When you’ve a é, ë or ě, do you advance the drawing cursor a single step between drawing the character and the shape? No you don’t, because the shape is part of the character and it is usually aligned with the character on the X axis.
here is the previous example in a more visual way,

While Latin characters’ diacritic (not really sure if these in Latin are also correctly to be called diacritics, anyways) is part of the character glyph itself, hence we draw a single quad. But for Arabic things are different, and each diacritic has it’s own glyph and needs it’s own quad when drawing. And even if you look at the glyphs atlas, you can still see that independence too.


Sound problematic, sounds complicated, but it is way simpler than it looks, now we’ve two issues, let’s fix them one by one.
1.Formation Issue
For refreshment, this is the code (from part 3 of the series) where we generate forms for Arabic codepoints so we can use them in font glyphs/atlas.
//some code to gather codepoints from the given string & store them in local list
...
//Update the forms of the temp codepoints list if applicable (Arabic range only)
{
u32 _prv = 0;
u32 _nxt = 0;
u32 _stp = 0;
//iterate through the text itself, not the code points, as now we compare codepoint with the ones before & fater in teh code points not from the string
for (u32 i = 0; i < _strCodepointCount; ++i)
{
u32 _cp = _codepointsForGivenString[i];
_nxt = i < _strCodepointCount - 1 ? _codepointsForGivenString[i + 1] : 0;
u32 _tcp = GetPresentationFormForChar(_prv, _nxt, _cp);
if (_tcp != -1)
{
_codepointsForGivenString[_stp ] = _tcp;
++_stp;
}
_prv = _cp;
//update the cache
for (u32 c = 0; c < Text->CodepointsCache.size(); ++c)
{
if (Text->CodepointsCache[c] == _cp)
{
Text->CodepointsCache[c] = _tcp;
//note, we should not set the debug CodepointsCachePreFormations here, this is where both CodepointsCache and CodepointsCachePreFormations should differ
//break as we don't want to go across the entire cache, we want only 1 occurance per codepoint
//this solves issues such as in Arabic's hhhhhh sequence, where first & last 'h' would differ from the middle ones
//if we don't break here, we end up with all hhhhhh using exact same form (ending) which is wrong, we need initial one as well as ending one
break;
}
}
}
}
...
//Some code to push the unique codepoints to the font codepoints list & pack the atlas if neededThis is the exact same thing from part 3, now we need to modify that, so the _nxt or _prv are never codepoints of a diacritic codepoint, and for that, we’ll be using the function IsDiacriticsOrSign() from part 3 of the series.
For the next codepoint to the currently in process codepoint, we do check if the next codepoint is diacritic or not, and we keep looking to the next after next and so on, till we find a “real” character, and then we consider this next.
//check for next letter if Tashkeel/Diacritics only in Arabic, so we skip considering it the next (else we will end up with all letters in isolated forms)
if(IsDiacriticsOrSign(_nxt))
{
u32 _nxtIncrementCheck = 1;
while (IsDiacriticsOrSign(_nxt) && i+_nxtIncrementCheck < _codepointsForGivenString.size())
{
_nxt = _codepointsForGivenString[i + _nxtIncrementCheck];
_nxtIncrementCheck++;
}
}For the previous one, it is much simpler, when we assign the current codepoint after it get modified to the _prv so we use it in the next loop iteration as a _prv, we can just check if the codepoint is diacritic or not.
//consider current is previous for the next iteration ONLY if it is not a Tashkeel/Diacritics
if (!IsDiacriticsOrSign(_cp))
{
_prv = _cp;
}So with these two simple changes, the entire block now looks like
//some code to gather codepoints from the given string & store them in local list
...
//Update the forms of the temp codepoints list if applicable (Arabic range only)
{
u32 _prv = 0;
u32 _nxt = 0;
u32 _stp = 0;
//iterate through the text itself, not the code points, as now we compare codepoint with the ones before & fater in teh code points not from the string
for (u32 i = 0; i < _strCodepointCount; ++i)
{
u32 _cp = _codepointsForGivenString[i];
_nxt = i < _strCodepointCount - 1 ? _codepointsForGivenString[i + 1] : 0;
//check for next letter if Tashkeel/Diacritics only in Arabic, so we skip considering it the next (else we will end up with all letters in isolated forms)
if(IsDiacriticsOrSign(_nxt))
{
u32 _nxtIncrementCheck = 1;
while (IsDiacriticsOrSign(_nxt) && i+_nxtIncrementCheck < _codepointsForGivenString.size())
{
_nxt = _codepointsForGivenString[i + _nxtIncrementCheck];
_nxtIncrementCheck++;
}
}
u32 _tcp = GetPresentationFormForChar(_prv, _nxt, _cp);
if (_tcp != -1)
{
_codepointsForGivenString[_stp ] = _tcp;
++_stp;
}
//consider current is previous for the next iteration ONLY if it is not a Tashkeel/Diacritics
if (!IsDiacriticsOrSign(_cp))
{
_prv = _cp;
}
//update the cache
for (u32 c = 0; c < Text->CodepointsCache.size(); ++c)
{
if (Text->CodepointsCache[c] == _cp)
{
Text->CodepointsCache[c] = _tcp;
//note, we should not set the debug CodepointsCachePreFormations here, this is where both CodepointsCache and CodepointsCachePreFormations should differ
//break as we don't want to go across the entire cache, we want only 1 occurance per codepoint
//this solves issues such as in Arabic's hhhhhh sequence, where first & last 'h' would differ from the middle ones
//if we don't break here, we end up with all hhhhhh using exact same form (ending) which is wrong, we need initial one as well as ending one
break;
}
}
}
}
...
//Some code to push the unique codepoints to the font codepoints list & pack the atlas if neededNow if we try to render again the same long text with diacritics, it will look like that..

We now got the correct forms again, with Right to Left and perfect wording in addition to diacritics. FANTASTIC! 🤩
Now we only have one little issue, if you’re not familiar with Arabic you indeed will never notice, that the diacritics are kinda offset to the left, and they are not on top of the correct owning characters.
2.Cursor Offset Issue
Now do you recall when mentioned earlier in this article that “diacritics are now treated as individual characters and this is wrong”?
That is exactly the issue, if we look to the wireframe, you’ll see that each diacritic regardless how tiny or large, it has it’s own quad, and as you know from earlier that the way drawing UI quads for a text object is by drawing character, then advance with X amount to draw the next one.

We do need to draw diacritics, but we don’t need to advance the drawing cursor after that, so we don’t cause in a wrong offset for everything.
This issue can be fixed at the text quad generation part of the code that we showcased it earlier in Part 2 of the series, here it is again for refreshment.
...
//some code before that
//these are used to hold the advance through the loop to the next vertices
f32 _x, _y;
//loop through all characters of the given string
for (u32 c = 0; c < _strLength; ++c)
{
...
//some code to fetch glyphs from the font data
//if not glyph in the font data for the given character, we return
//the glyphs are read earlier via stb_truetype.h and stored in a data structure and baked into an atlas
if (!_glyph)
return;
//locals to hold the per vertex info that we will feed to the renderer
f32 _minX, _maxX, _minY, _maxY, _uvminX, _uvmaxX, _uvminY, _uvmaxY;
//We draw vertices at the cached direction of the text object
if (Text->TextDirection == ETEXTDirection::TEXT_DIRECTION_RIGHT_TO_LEFT)
{
_minX = _x + _glyph->OffsetX;
_minY = _y + _glyph->OffsetY;
_maxX = _minX + _glyph->Width;
_maxY = _minY + _glyph->Height;
_uvminX = (f32)_glyph->X / Text->Font->AtlasSizeX;
_uvmaxX = (f32)(_glyph->X + _glyph->Width) / Text->Font->AtlasSizeX;
_uvminY = (f32)_glyph->Y / Text->Font->AtlasSizeY;
_uvmaxY = (f32)(_glyph->Y + _glyph->Height) / Text->Font->AtlasSizeY;
}
else
{
_minX = _x + _glyph->OffsetX;
_minY = _y + _glyph->OffsetY;
_maxX = _minX + _glyph->Width;
_maxY = _minY + _glyph->Height;
_uvminX = (f32)_glyph->X / Text->Font->AtlasSizeX;
_uvmaxX = (f32)(_glyph->X + _glyph->Width) / Text->Font->AtlasSizeX;
_uvminY = (f32)_glyph->Y / Text->Font->AtlasSizeY;
_uvmaxY = (f32)(_glyph->Y + _glyph->Height) / Text->Font->AtlasSizeY;
}
//following code to make the actual vertices from previous info, push them into the vertex buffer, generate indices, push into the index buffer, and proceed to render
...
}We first, need to declare a new local variable, to keep tracking of the width of the current glyph we drawing
//usually needed to shift the glyphs for the Diacritics/Tashkeel codepoints, as we don't want to consider them as "independent" characters
//that are drawn at next to the previous drawn character, so we always shift back & forth with the size of the glyph (the diacritic glyph)
u16 _currentGlyphWidth = 0;Then before we generate the location of the vertices for the quad, we need to se the value of that new variable to the width of the glyph we’re drawing, and if we’re going to draw a diacritic, we need to shift back with the amount of the glyph widht.
//store the width of the current glyph, needed for Arabic diacritics
_currentGlyphWidth = _glyph->Width;
//if we drawing a Diacritics/Tashkeel codepoint, then we shift back, so it draw on top of the previous character, not next to it as independent character
if (IsDiacriticsOrSign(_codepoint))
_x -= _currentGlyphWidth;When everything is done, and we generated the the correct quad info that we push to vertex & index buffer, we can reset the cursor horizontally back again,
//if we drawing a Diacritics/Tashkeel codepoint, then we re-compensate the previous shift back, so next character draw correctly
if (IsDiacriticsOrSign(_codepoint))
_x += _currentGlyphWidth;Now putting these 3 modifications in context of the code that is generating the vertices, it would be like
...
//some code before that
//these are used to hold the advance through the loop to the next vertices
f32 _x, _y;
//loop through all characters of the given string
for (u32 c = 0; c < _strLength; ++c)
{
...
//some code to fetch glyphs from the font data
//if not glyph in the font data for the given character, we return
//the glyphs are read earlier via stb_truetype.h and stored in a data structure and baked into an atlas
if (!_glyph)
return;
//usually needed to shift the glyphs for the Diacritics/Tashkeel codepoints, as we don't want to consider them as "independent" characters
//that are drawn at next to the previous drawn character, so we always shift back & forth with the size of the glyph (the diacritic glyph)
u16 _currentGlyphWidth = 0;
//locals to hold the per vertex info that we will feed to the renderer
f32 _minX, _maxX, _minY, _maxY, _uvminX, _uvmaxX, _uvminY, _uvmaxY;
//store the width of the current glyph, needed for Arabic diacritics
_currentGlyphWidth = _glyph->Width;
//if we drawing a Diacritics/Tashkeel codepoint, then we shift back, so it draw on top of the previous character, not next to it as independent character
if (IsDiacriticsOrSign(_codepoint))
_x -= _currentGlyphWidth;
//We draw vertices at the cached direction of the text object
if (Text->TextDirection == ETEXTDirection::TEXT_DIRECTION_RIGHT_TO_LEFT)
{
_minX = _x + _glyph->OffsetX;
_minY = _y + _glyph->OffsetY;
_maxX = _minX + _glyph->Width;
_maxY = _minY + _glyph->Height;
_uvminX = (f32)_glyph->X / Text->Font->AtlasSizeX;
_uvmaxX = (f32)(_glyph->X + _glyph->Width) / Text->Font->AtlasSizeX;
_uvminY = (f32)_glyph->Y / Text->Font->AtlasSizeY;
_uvmaxY = (f32)(_glyph->Y + _glyph->Height) / Text->Font->AtlasSizeY;
}
else
{
_minX = _x + _glyph->OffsetX;
_minY = _y + _glyph->OffsetY;
_maxX = _minX + _glyph->Width;
_maxY = _minY + _glyph->Height;
_uvminX = (f32)_glyph->X / Text->Font->AtlasSizeX;
_uvmaxX = (f32)(_glyph->X + _glyph->Width) / Text->Font->AtlasSizeX;
_uvminY = (f32)_glyph->Y / Text->Font->AtlasSizeY;
_uvmaxY = (f32)(_glyph->Y + _glyph->Height) / Text->Font->AtlasSizeY;
}
//following code to make the actual vertices from previous info, push them into the vertex buffer,
...
//if we drawing a Diacritics/Tashkeel codepoint, then we re-compensate the previous shift back, so next character draw correctly
if (IsDiacriticsOrSign(_codepoint))
_x += _currentGlyphWidth;
//generate indices, push into the index buffer, and proceed to render
...
}Now if we give it a go…

It looks just perfect, and with another font that is not expected to have diacritics (not original old type of font like the previous one)

And in action…

Here is much larger & much more complicated text block
& btw, the entire system by now is fine on gaming consoles, i can only show on Switch for now for the obvious reasons!
-m