Arabic Decoding for Games & Game Engines – Part 3: Formations
Parts of the Series
This series consist of 6 parts:
- Arabic Decoding for Games & Game Engines – Part 1: Challenges
- Arabic Decoding for Games & Game Engines – Part 2: Decoding
- Arabic Decoding for Games & Game Engines – Part 3: Formations
- Arabic Decoding for Games & Game Engines – Part 4: Lam-Aleph
- Arabic Decoding for Games & Game Engines – Part 5: Diacritics
- Arabic Decoding for Games & Game Engines – Part 6: Multi-Language
Disclaimer
Big part of the work i’ve done in this 3rd part of the series of Arabic decoding was based on the work that can be found in this decade old github project that was made by Wael El Oraiby.
So now we have a Right to Left text rendered with correct ordering of characters, but they looks wrong, as they’re not respecting any of the formations and all characters are presented in the Isolated form of the character, which is the default value for any character we decode from the given string.
The goal now is to take every codepoint in the string, and get the proper form (initial, middle, final or isolated) based on it’s location in the string, or in another meaning, based on the character before and the one after. But even with that how can we give a decision?
The best way to do that, if we can in “some way” sort all the variations of the characters forms into an organized table that we can then go through it to fetch a form for a given character/codepoint based on what before and after it in the word/phrase.
Of course first sus for that would be hashtables, but this is no go, due to the cost and the fact that UI could be ticking every frame!
With some googling, i found an interesting discussion on stackoverflow where the guys spoke about building an array that includes all the characters forms, and the entries are ordered based on the character location in a word!
With more searching and iterations on the idea, i found the is the best approach, and found out multiple projects already using it, so we build an array like that
//we will need these defines to access the elements of the [4] array below in a tidy & recognized way
#define ARABIC_UNICODE_LETTER_FORM_ISOLATED 0 //aalt - Access All Alternates
#define ARABIC_UNICODE_LETTER_FORM_END 1 //fina - Terminal Forms
#define ARABIC_UNICODE_LETTER_FORM_BEGIN 2 //init - Initial Forms
#define ARABIC_UNICODE_LETTER_FORM_MIDDLE 3 //medi - Medial Forms
typedef i32 perCharacterMajorForms[4];//array of 4 forms base don the 4 majors forms (isolate, ending, initial & middle)
typedef perCharacterMajorForms allPossibleForms[2];//first array is the 4 forms, second array is the Ligatures
/*
0: Isolated form
1: End form
2: Begin form
3: Middle form
*/
static allForms ArabicPresentationForms[] =
{
//forms Ligatures
//{Isolated, Ending, Initial, Middle} , {Isolated, Ending, Initial, Middle}
{ {0xFE80, 0xFE80, 0, 0}, {-1, -1, 0, 0} }, //[0] ء
{ {0xFE81, 0xFE82, 0, 0}, {-1, -1, 0xFEF5, 0xFEF6} }, //[1] آ
{ {0xFE83, 0xFE84, 0, 0}, {-1, -1, 0xFEF7, 0xFEF8} }, //[2] أ
{ {0xFE85, 0xFE86, 0, 0}, {-1, -1, 0, 0} }, //[3] ؤ
{ {0xFE87, 0xFE88, 0, 0}, {-1, -1, 0xFEF9, 0xFEFA} }, //[4] ﺇ
{ {0xFE89, 0xFE8A, 0xFE8B, 0xFE8C}, {-1, -1, 0, 0} }, //[5] ﺉ
{ {0xFE8D, 0xFE8E, 0, 0}, {-1, -1, 0xFEFB, 0xFEFC} }, //[6] ﺍ
{ {0xFE8F, 0xFE90, 0xFE91, 0xFE92}, {-1, -1, 0, 0} }, //[7] ب
{ {0xFE93, 0xFE94, 0, 0}, {-1, -1, 0, 0} }, //[8] ﺓ
{ {0xFE95, 0xFE96, 0xFE97, 0xFE98}, {-1, -1, 0, 0} }, //[9] ت
{ {0xFE99, 0xFE9A, 0xFE9B, 0xFE9C}, {-1, -1, 0, 0} }, //[10] ث
{ {0xFE9D, 0xFE9E, 0xFE9F, 0xFEA0}, {-1, -1, 0, 0} }, //[11] ج
{ {0xFEA1, 0xFEA2, 0xFEA3, 0xFEA4}, {-1, -1, 0, 0} }, //[12] ح
{ {0xFEA5, 0xFEA6, 0xFEA7, 0xFEA8}, {-1, -1, 0, 0} }, //[13] خ
{ {0xFEA9, 0xFEAA, 0, 0}, {-1, -1, 0, 0} }, //[14] د
{ {0xFEAB, 0xFEAC, 0, 0}, {-1, -1, 0, 0} }, //[15] ذ
{ {0xFEAD, 0xFEAE, 0, 0}, {-1, -1, 0, 0} }, //[16] ر
{ {0xFEAF, 0xFEB0, 0, 0}, {-1, -1, 0, 0} }, //[17] ز
{ {0xFEB1, 0xFEB2, 0xFEB3, 0xFEB4}, {-1, -1, 0, 0} }, //[18] س
{ {0xFEB5, 0xFEB6, 0xFEB7, 0xFEB8}, {-1, -1, 0, 0} }, //[19] ش
{ {0xFEB9, 0xFEBA, 0xFEBB, 0xFEBC}, {-1, -1, 0, 0} }, //[20] ص
{ {0xFEBD, 0xFEBE, 0xFEBF, 0xFEC0}, {-1, -1, 0, 0} }, //[21] ض
{ {0xFEC1, 0xFEC2, 0xFEC3, 0xFEC4}, {-1, -1, 0, 0} }, //[22] ط
{ {0xFEC5, 0xFEC6, 0xFEC7, 0xFEC8}, {-1, -1, 0, 0} }, //[23] ظ
{ {0xFEC9, 0xFECA, 0xFECB, 0xFECC}, {-1, -1, 0, 0} }, //[24] ع
{ {0xFECD, 0xFECE, 0xFECF, 0xFED0}, {-1, -1, 0, 0} }, //[25] غ
{ { 0, 0, 0, 0}, {-1, -1, 0, 0} }, //[26]
{ { 0, 0, 0, 0}, {-1, -1, 0, 0} }, //[27]
{ { 0, 0, 0, 0}, {-1, -1, 0, 0} }, //[28]
{ { 0, 0, 0, 0}, {-1, -1, 0, 0} }, //[29]
{ { 0, 0, 0, 0}, {-1, -1, 0, 0} }, //[30]
{ { 0x640, 0x640, 0x640, 0x640}, {-1, -1, 0, 0} }, //[31] ـ
{ {0xFED1, 0xFED2, 0xFED3, 0xFED4}, {-1, -1, 0, 0} }, //[32] ف
{ {0xFED5, 0xFED6, 0xFED7, 0xFED8}, {-1, -1, 0, 0} }, //[33] ق
{ {0xFED9, 0xFEDA, 0xFEDB, 0xFEDC}, {-1, -1, 0, 0} }, //[34] ك
{ {0xFEDD, 0xFEDE, 0xFEDF, 0xFEE0}, {-1, -1, 0, 0} }, //[35] ل
{ {0xFEE1, 0xFEE2, 0xFEE3, 0xFEE4}, {-1, -1, 0, 0} }, //[36] م
{ {0xFEE5, 0xFEE6, 0xFEE7, 0xFEE8}, {-1, -1, 0, 0} }, //[37] ن
{ {0xFEE9, 0xFEEA, 0xFEEB, 0xFEEC}, {-1, -1, 0, 0} }, //[38] ه
{ {0xFEED, 0xFEEE, 0, 0}, {-1, -1, 0, 0} }, //[39] و
{ {0xFEEF, 0xFEF0, 0, 0}, {-1, -1, 0, 0} }, //[40] ﻯ
{ {0xFEF1, 0xFEF2, 0xFEF3, 0xFEF4}, {-1, -1, 0, 0} }, //[41] ﻱ
};
//empty entires [26 : 30] is to compenstae while traversing the array, otherwise the order of letters is messed up.Keep in mind, that Arabic presentation forms are in the range
U+FB50 to U+FDFF Arabic Presentation Forms A
U+FE70 to U+FEFF Arabic Presentation Forms B
For the second array in each line, this is basically for Ligatures, if you’re not familiar with them you can use something like Fontdrop website to check the content of your given font file, my current test file includes these 8 ligatures for the Aleph and Lam letters (others are for diacritics which we will cover later in the series), which is covering the ones above (0xFEF5, 0xFEF6, 0xFEF7, 0xFEF8, 0xFEF9, 0xFEFA, 0xFEFB, 0xFEFC)
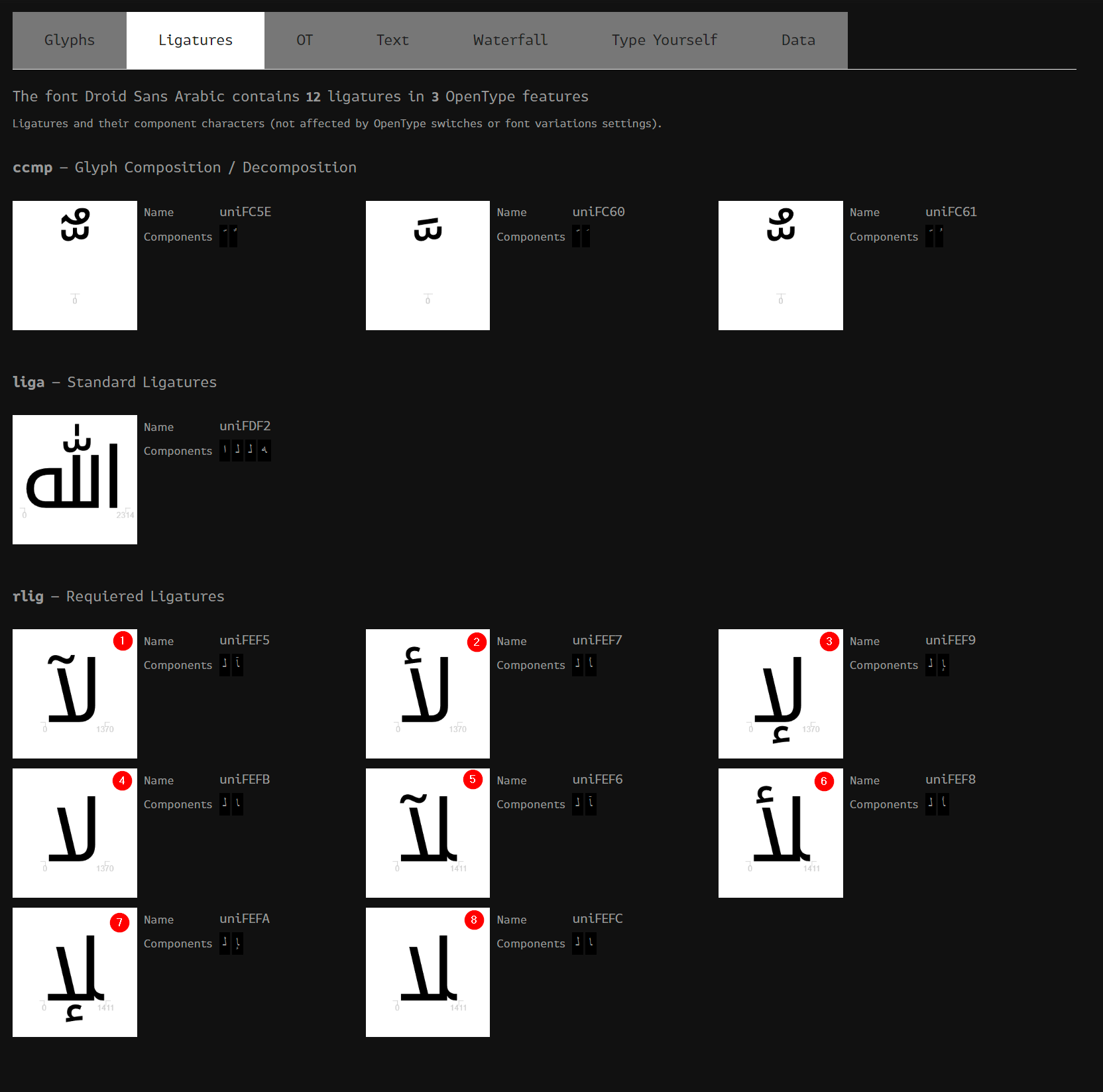
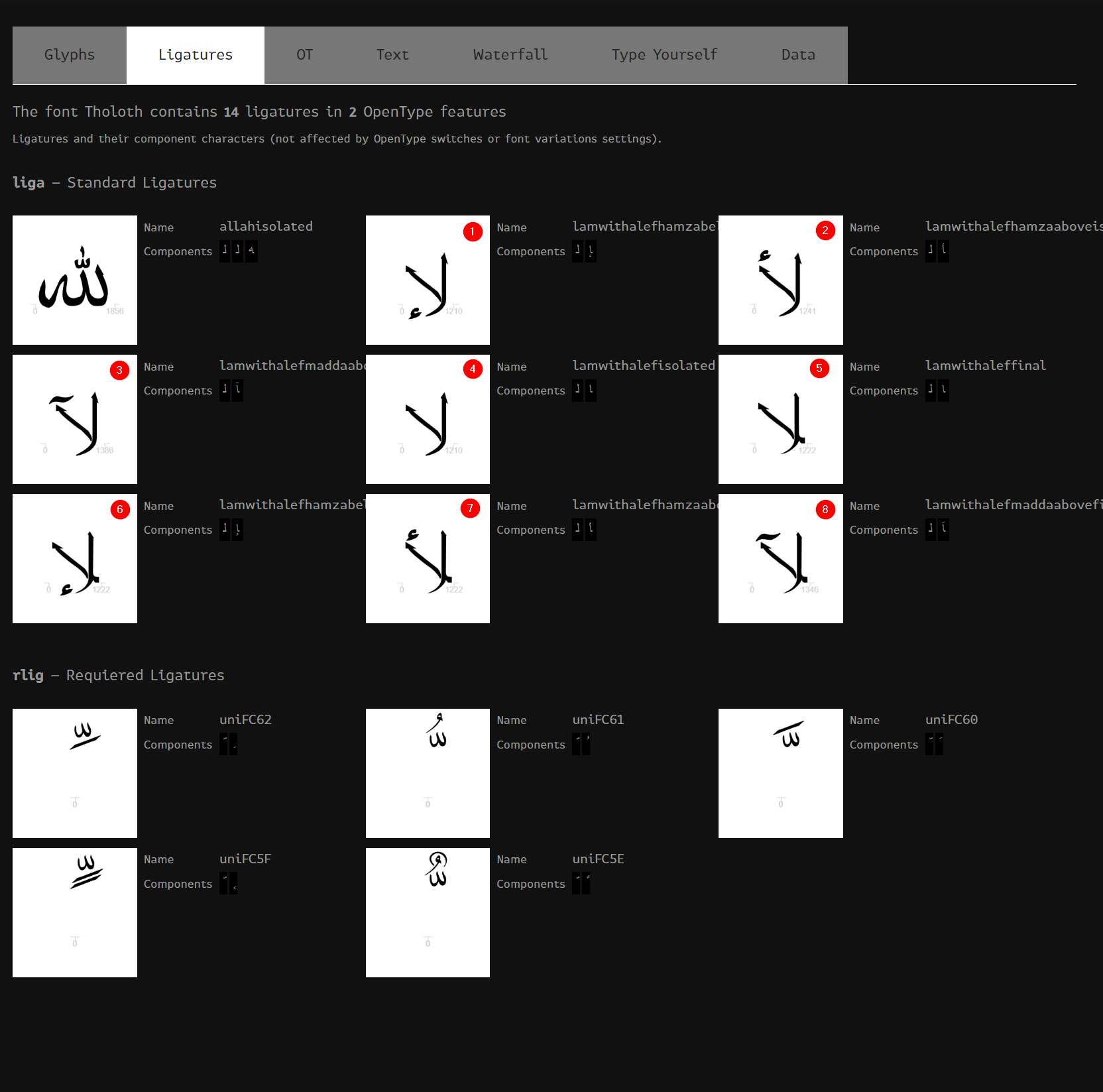
Now with that previous array ready, we can’t just go through it can fetch values, we would need some helper utility functions to do some checks and return true or false. These are as follow..
I tried to put as much notes as possible for that. But in general, these are checking some core linking rules for the characters based on the the previous or next given codepoint to the currently in process codepoint.
//Unicode list of blocks related to Arabic: https://en.wikipedia.org/wiki/Unicode_block
//Plane Block Range Block Name Codepoints Assigned Characters Scripts
//----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
//[0 BMP] U+0600..U+06FF Arabic 256 256 Arabic (238 characters), Common (6 characters), Inherited (12 characters)
//[0 BMP] U+0750..U+077F Arabic Supplement 48 48 Arabic
//[0 BMP] U+0870..U+089F Arabic Extended B 41 41 Arabic
//[0 BMP] U+08A0..U+08FF Arabic Extended A 96 96 Arabic
//[0 BMP] U+FB50..U+FDFF Arabic Presentation Forms A 688 631 Arabic (629 characters), Common (2 characters)
//[0 BMP] U+FE70..U+FEFF Arabic Presentation Forms B 144 141 Arabic (140 characters), Common (1 character)
//[1 SMP] U+10E60..U+10E7F Rumi Numeral SYmbols 32 31 Arabic
//[1 SMP] U+10EC0..U+10EFF Arabic Extended C 64 3 Arabic
//[1 SMP] U+1EE00..U+1EEFF Arabic Mathematical Alphabetic Symbols 256 143 Arabic
//================================================================================================================================================================================================================
//Arabic Range
#define ARABIC_RANGE_START 0x621
#define ARABIC_RANGE_END 0x64A
//Lam & Aleph have some cases, let's keep their codepoints accessible in easy way
#define ARABIC_UNICODE_LETTER_LAM 0x644
#define ARABIC_UNICODE_LETTER_ALEPH 0x627
#define ARABIC_UNICODE_LETTER_LAM_ALEPH 0xFEFC
#define ARABIC_UNICODE_LETTER_LAM_ALEPH_ISOLATED 0xFEFB
//Check if the given codepoint is in the Arabic range
static inline b8 IsCharacterInArabicCodepointRange(u32 codepoint)
{
return codepoint >= ARABIC_RANGE_START && codepoint <= ARABIC_RANGE_END;
}
//Check if a given codepoint is a Lam-Aleph type.
//This happens when the given codepoint is Lam and the next codepoint is an Arabic character and the initial ligatures for the next character is valid value (in the ligatures array)
static inline b8 IsLamAlef(u32 codepoint, u32 next)
{
return codepoint == ARABIC_UNICODE_LETTER_LAM && IsCharacterInArabicCodepointRange(next) && ArabicPresentationForms[next - ARABIC_RANGE_START][1][ARABIC_UNICODE_LETTER_FORM_BEGIN] != 0;
}
//Check if there is a Lam before the given codepoint
//This happens when the previous codepoint is Lam and the current codepoint is an Arabic codepoint and the initial ligatures for the current character is valid value (in the ligatures array)
static inline b8 IsAlefBeforeLam(u32 prev, u32 codepoint)
{
return prev == ARABIC_UNICODE_LETTER_LAM && IsCharacterInArabicCodepointRange(codepoint) && ArabicPresentationForms[codepoint - ARABIC_RANGE_START][1][ARABIC_UNICODE_LETTER_FORM_BEGIN] != 0;
}
//Check for linking of the the given codepoint
//This happens when the given codepoitn is an Arabic codepoint and the middle form for the current codepoint isolated form is valid value (in the 4 forms array)
static inline b8 IsLinkingType(u32 codepoint)
{
return IsCharacterInArabicCodepointRange(codepoint) && ArabicPresentationForms[codepoint - ARABIC_RANGE_START][0][ARABIC_UNICODE_LETTER_FORM_MIDDLE] != 0;
}
//Check if the given codepoint is for a Diacritics or sign,
//Unfortunatly the ranges are scattered for the different signs
static inline b8 IsDiacriticsOrSign(u32 codepoint)
{
return
(codepoint >= ARABIC_TASHKEEL_A_START && codepoint <= ARABIC_TASHKEEL_A_END) ||
(codepoint >= ARABIC_TASHKEEL_B_START && codepoint <= ARABIC_TASHKEEL_B_END) ||
(codepoint >= ARABIC_TASHKEEL_C_START && codepoint <= ARABIC_TASHKEEL_C_END);
}Now we come to the core function, that does all the magic, which is giving us a correct form codepoint for a given character based on the one before & the one after it in the word
static u32 GetPresentationFormForChar(u32 prev, u32 next, u32 codepoint)
{
//early out if not an arabic letter
if (!IsCharacterInArabicCodepointRange(codepoint))
{
return codepoint;
}
//bools to check for Aleph & Lam mixing speical cases (compound or ligatures)
b8 _isLamAleph = IsLamAlef(codepoint, next);
b8 _isAlefBeforeLam = IsAlefBeforeLam(prev, codepoint);
b8 _isAlephOrLamCase = _isLamAleph || _isAlefBeforeLam;
//get the form from the array:
//first get the index of the from from the 4 forms (linkage type & being aleph/lam case is defining that)
//then get the character reference (which one from 0 to 41 from the array entires)
//naviage through the array to return the proper form (basic for or ligatures)
u32 _idx = (((_isAlephOrLamCase | IsCharacterInArabicCodepointRange(next)) & IsLinkingType(codepoint)) << 1) | IsLinkingType(prev);
u32 _ref = next * _isLamAleph + codepoint * (!_isLamAleph) - ARABIC_RANGE_START;
return ArabicPresentationForms[_ref][_isAlephOrLamCase][_idx];
}Now with that function ready, we can use it in one place, within the font atlas generation, where we evaluate all the given characters pers string, and deciding if we need to add some new glyphs to the atlas or they’re already included from previous use.
The way my system works is like that, i do have 2 code paths, one that with every string change we do evaluate the font glyphs we baked into the font atlas, and then we either add (if new glyph present) or skip (if the given glyph found already). The other code path is where at the start of the app, i do generate large atlas, with all codepoints found in the Arabic range[s], but this gives me a very large atlas. And with that said, most of the time, i use the earlier version, but why?
The simplest answer is that i want to test the upper bound, and see how large the glyphs atlas could be, i don’t want to give a hypothetical size like 2048*2048 and live with a half empty rendertarget, instead, i was to keep observing how large my atlas could get, and then i can lock that value as fixed glyphs atlas size.
Anyway, back to the glyphs storing, here is where we check for correct forms, and if we’ve them in atlas or not. In a first run to the parent function that include that snippet, pretty much every codepoint form returned from GetPresentationFormForChar() will be new and hence will be added to the atlas.
//some code to gather codepoints from the given string & store them in local list
...
//Update the forms of the temp codepoints list if applicable (Arabic range only)
{
u32 _prv = 0;
u32 _nxt = 0;
u32 _stp = 0;
//iterate through the text itself, not the code points, as now we compare codepoint with the ones before & fater in teh code points not from the string
for (u32 i = 0; i < _strCodepointCount; ++i)
{
u32 _cp = _codepointsForGivenString[i];
_nxt = i < _strCodepointCount - 1 ? _codepointsForGivenString[i + 1] : 0;
u32 _tcp = GetPresentationFormForChar(_prv, _nxt, _cp);
if (_tcp != -1)
{
_codepointsForGivenString[_stp ] = _tcp;
++_stp;
}
_prv = _cp;
//update the cache
for (u32 c = 0; c < Text->CodepointsCache.size(); ++c)
{
if (Text->CodepointsCache[c] == _cp)
{
Text->CodepointsCache[c] = _tcp;
//note, we should not set the debug CodepointsCachePreFormations here, this is where both CodepointsCache and CodepointsCachePreFormations should differ
//break as we don't want to go across the entire cache, we want only 1 occurance per codepoint
//this solves issues such as in Arabic's hhhhhh sequence, where first & last 'h' would differ from the middle ones
//if we don't break here, we end up with all hhhhhh using exact same form (ending) which is wrong, we need initial one as well as ending one
break;
}
}
}
}
...
//Some code to push the unique codepoints to the font codepoints list & pack the atlas if neededOne thing i want to mention here (which is part of my engine design), that each UIText object has a CodepointsCache list that you see me altering it’s content, which includes all the final copoints (after any manipulation). Also has a debug only member CodepointsCachePreFormations similar to the cache one. Both list get initialized when a text object created & re-set when a text object get it’s text changed. And this way i can read from the cache list at draw time right away, and don’t have to do any evaluation (like checking if a codepoint is Arabic or not, or like looking for forms) to alter codepoints at anytime. At the same time i can use the pre-formation list (debug only) to learn about what codepoints been changed and what was the codepoints before that change. This is why when we succeed above to change the form of a codepoint, we don’t update the CodepointsCachePreFormations .
struct UIText
{
u32 ID;
EUITextType Type;
ETEXTDirection TextDirection;
Transform Transformation;
MRIFont* Font;
MRIRenderbuffer VertexBuffer;
MRIRenderbuffer IndexBuffer;
char* ContentStr;
std::vector<i32> CodepointsCache;
#ifdef _DEBUG
std::vector<i32> CodepointsCachePreFormations;//this holds the raw codepoint for the characters, without any formations processing
#endif//_DEBUG
};And with atlas glyphs baking for the correct forms in place, and using the exact same codepoint reading-drawing code of the English characters that we discussed in the previous article, when run the game, we can have Arabic that looks like this!

Which is correct Arabic (apart from the missing glyphs). And if we hook different fonts, we keep seeing all the same


And for that last cute font, generated quads from right to left are like

And the generated atlas (considering i force generating for only characters presented in the application, it will includes only glyphs for that exact character forms for that only text in the application in that test) + a box glyph that i force in any glyphs atlas to draw missing codepoints.

Yes a lot of wasted atlas size, but this is only for the current test, a final atlas in the engine is much more tight.
For the missing characters from the text we’ve now, this is a little special case subjective to my use of cached codepoints (mentioned above) that we will discuss in the next part of the series.
Because this part of the series is the most interesting one, by the end of this section, i wanted to leave some useful resource & links that was helpful, either in understanding codepoints for Arabic or for services that was very helpful during the Arabic decoding journey
Discussions:
https://stackoverflow.com/questions/33718144/do-arabic-characters-have-different-unicode-code-points-based-on-position-in-str
https://en.wikipedia.org/wiki/Arabic_script_in_Unicode
https://en.wikipedia.org/wiki/Unicode_block
https://en.wikipedia.org/wiki/Arabic_(Unicode_block)
https://en.wikipedia.org/wiki/Arabic_Presentation_Forms-B
Services
https://codepoints.net/
https://fontdrop.info/
https://jrgraphix.net/r/Unicode/
-m